
 游雁
游雁
17 muutettua tiedostoa jossa 15 lisäystä ja 23 poistoa
+ 5
- 5
README_zh.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 4
- 4
docs/index.rst
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 1
- 0
docs/runtime
|
||
|
||
BIN
docs/runtime/demo.gif
{kind=link}
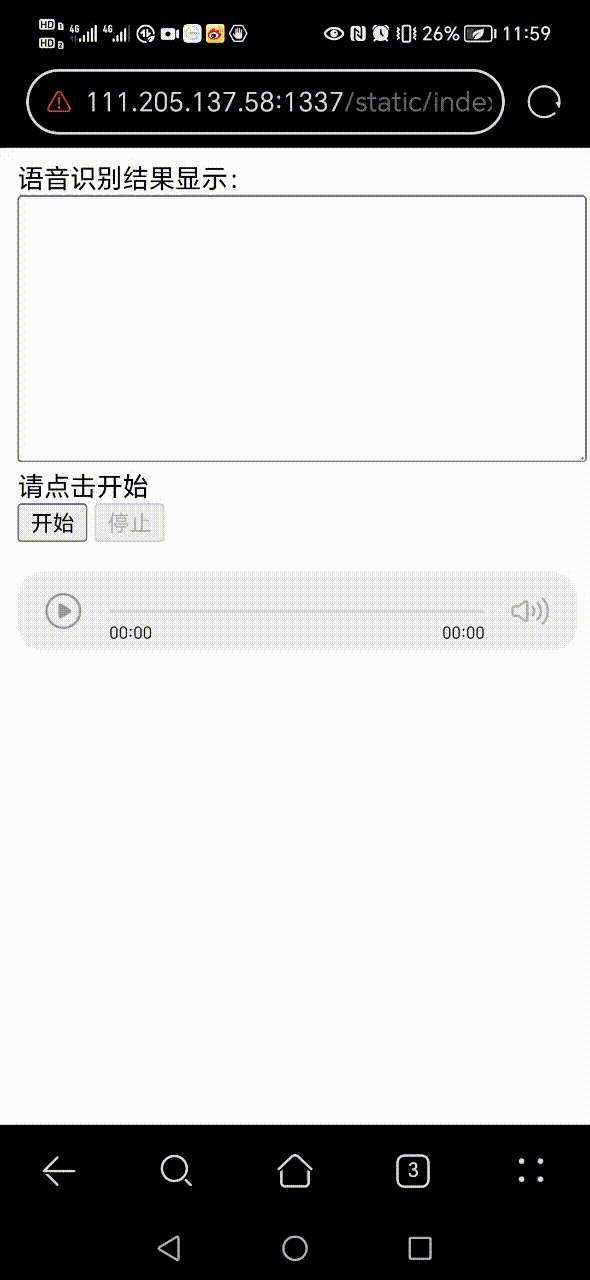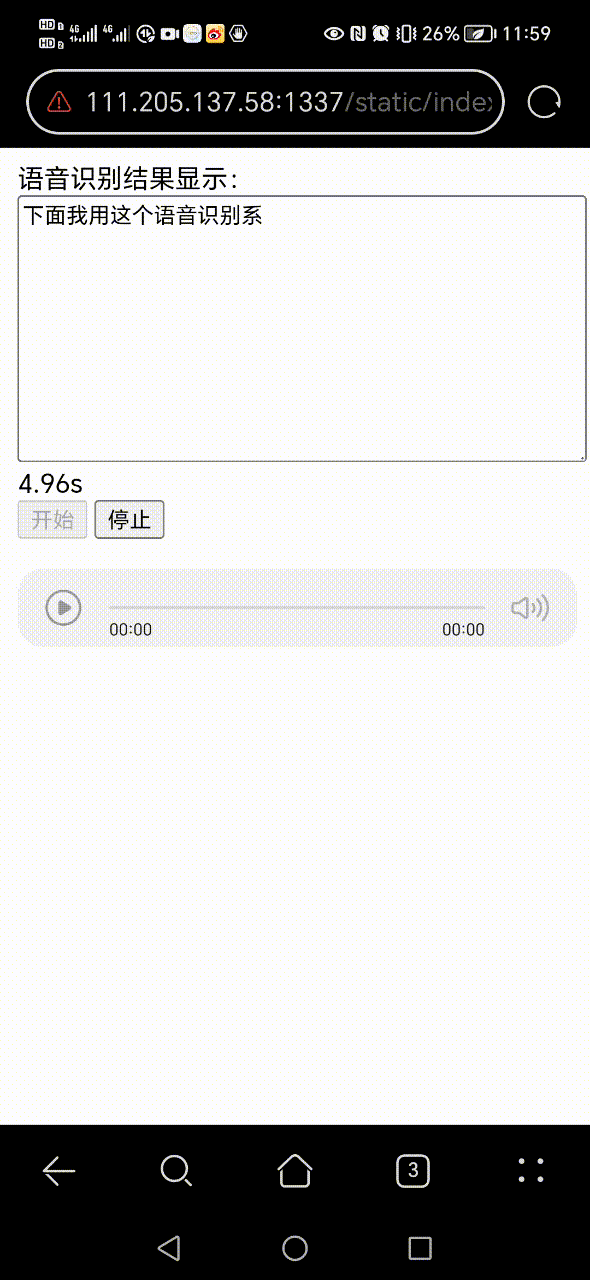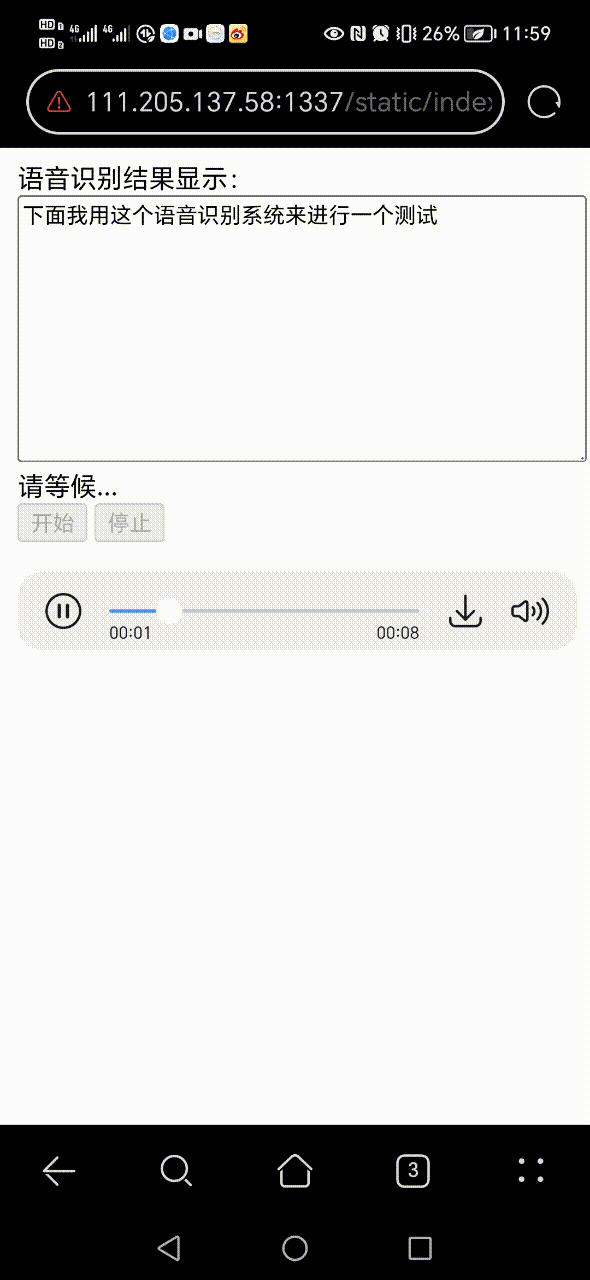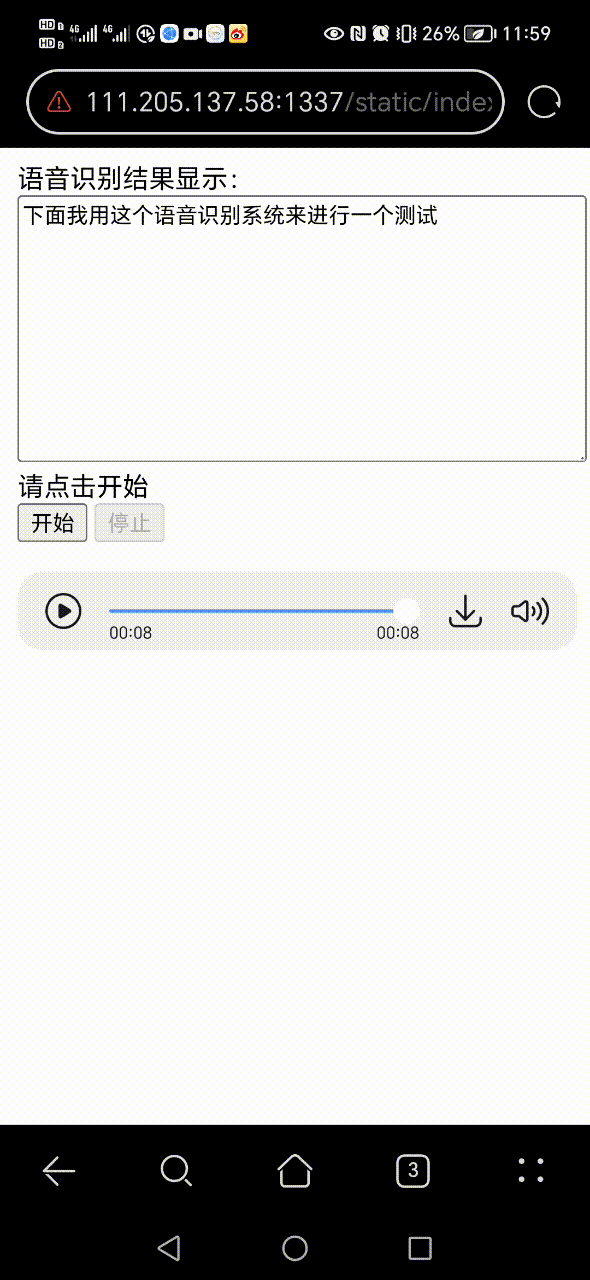
+ 0
- 1
docs/runtime/export.md
|
||
|
||
+ 0
- 1
docs/runtime/grpc_cpp.md
|
||
|
||
+ 0
- 1
docs/runtime/grpc_python.md
|
||
|
||
+ 0
- 1
docs/runtime/html5.md
|
||
|
||
BIN
docs/runtime/img.png
{kind=link}

+ 0
- 1
docs/runtime/libtorch_python.md
|
||
|
||
+ 0
- 1
docs/runtime/onnxruntime_cpp.md
|
||
|
||
+ 0
- 1
docs/runtime/onnxruntime_python.md
|
||
|
||
+ 0
- 1
docs/runtime/websocket_cpp.md
|
||
|
||
+ 0
- 1
docs/runtime/websocket_python.md
|
||
|
||
+ 1
- 3
egs_modelscope/asr/TEMPLATE/README_zh.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
runtime/docs/images/sdk_roadmap.jpg
{kind=link}
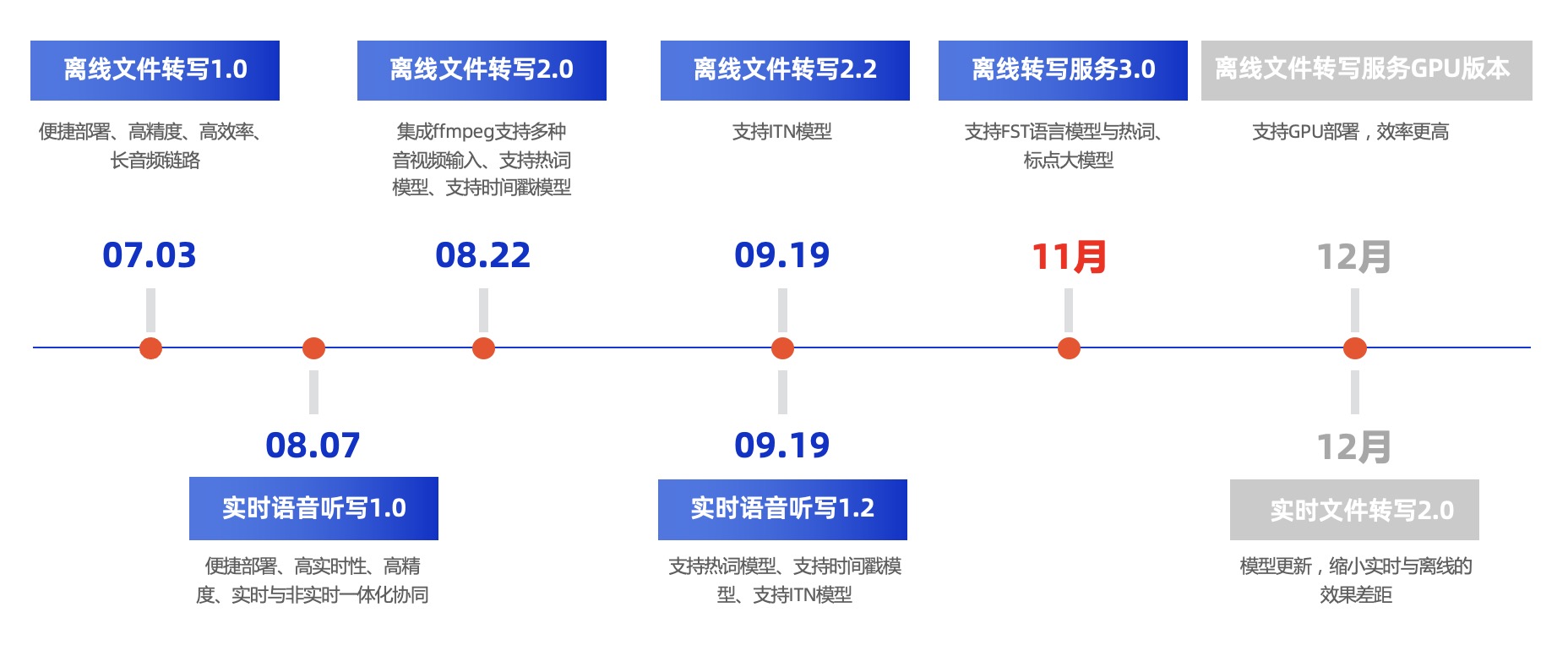
+ 4
- 2
runtime/readme_cn.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||